Codefuse-ChatBot: Development by Private Knowledge Augmentation
![]()
![]()


🔔 Updates
- [2023.09.15] Sandbox features for local/isolated environments are now available, implementing specified URL knowledge retrieval based on web crawling.
📜 Contents
🤝 Introduction
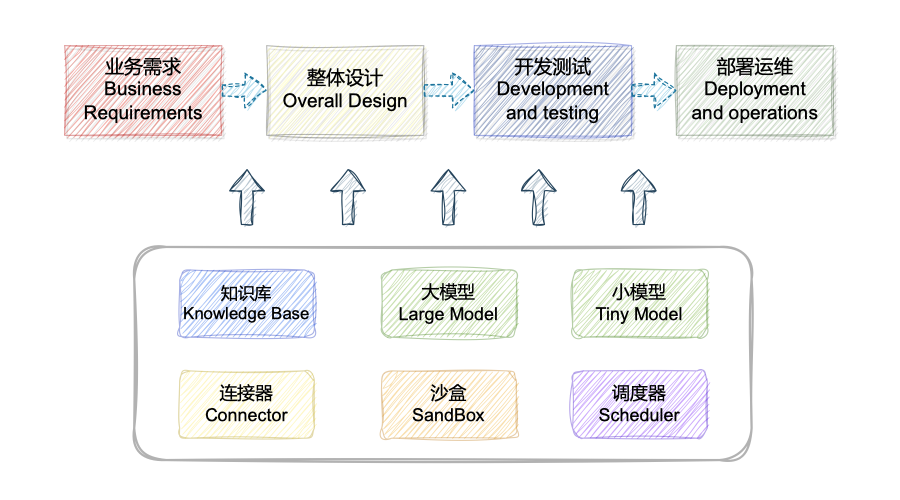
💡 The aim of this project is to construct an AI intelligent assistant for the entire lifecycle of software development, covering design, coding, testing, deployment, and operations, through Retrieval Augmented Generation (RAG), Tool Learning, and sandbox environments. It transitions gradually from the traditional development and operations mode of querying information from various sources and operating on standalone, disparate platforms to an intelligent development and operations mode based on large-model Q&A, changing people's development and operations habits.
- 📚 Knowledge Base Management: Professional high-quality Codefuse knowledge base + enterprise-level knowledge base self-construction + dialogue-based fast retrieval of open-source/private technical documents.
- 🐳 Isolated Sandbox Environment: Enables quick compilation, execution, and testing of code.
- 🔄 React Paradigm: Supports code self-iteration and automatic execution.
- 🛠️ Prompt Management: Manages prompts for various development and operations tasks.
- 🚀 Conversation Driven: Automates requirement design, system analysis design, code generation, development testing, deployment, and operations.
🌍 Relying on open-source LLM and Embedding models, this project can achieve offline private deployments based on open-source models. Additionally, this project also supports the use of the OpenAI API.
👥 The core development team has been long-term focused on research in the AIOps + NLP domain. We initiated the CodefuseGPT project, hoping that everyone could contribute high-quality development and operations documents widely, jointly perfecting this solution to achieve the goal of "Making Development Seamless for Everyone."
🌍 Relying on open-source LLM and Embedding models, this project can achieve offline private deployments based on open-source models. Additionally, this project also supports the use of the OpenAI API.
👥 The core development team has been long-term focused on research in the AIOps + NLP domain. We initiated the DevOpsGPT project, hoping that everyone could contribute high-quality development and operations documents widely, jointly perfecting this solution to achieve the goal of "Making Development Seamless for Everyone."
🧭 Technical Route
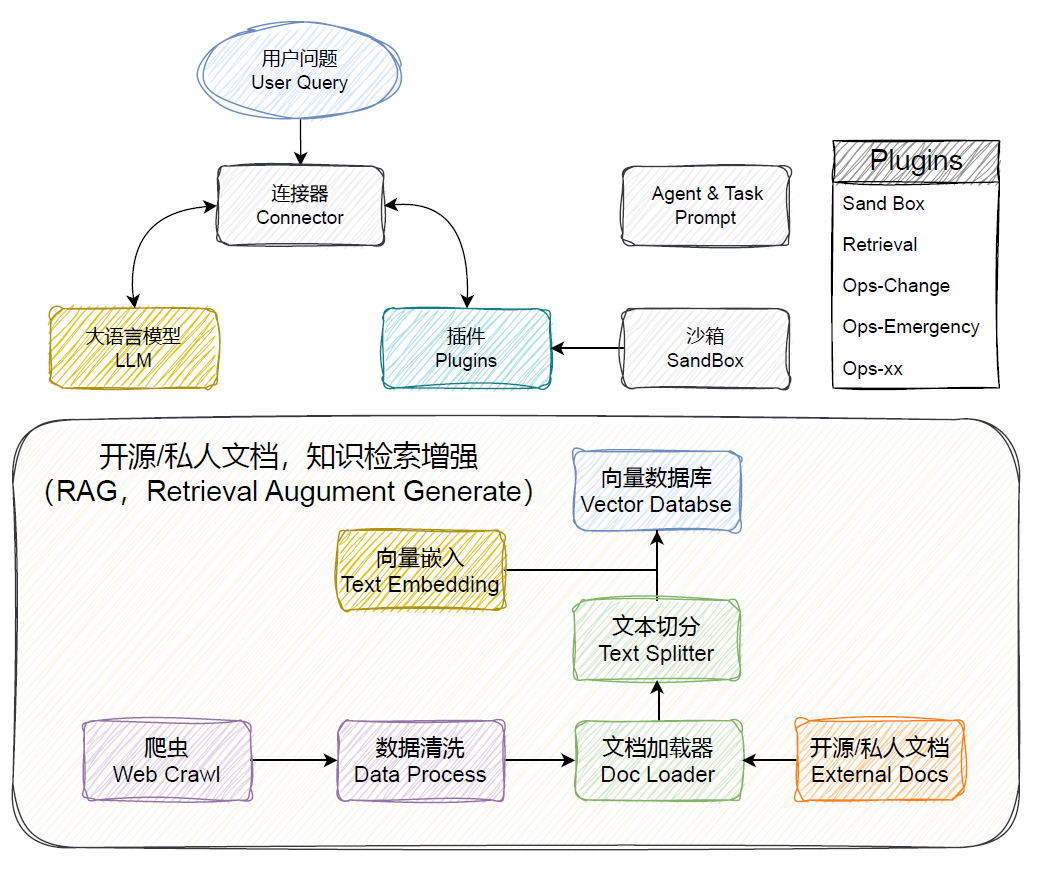
- 🕷️ Web Crawl: Implements periodic web document crawling to ensure data timeliness and relies on continuous supplementation from the open-source community.
- 🗂️ DocLoader & TextSplitter: Cleans, deduplicates, and categorizes data crawled from various sources and supports the import of private documents.
- 🗄️ Vector Database: Integrates Text Embedding models to embed documents and store them in Milvus.
- 🔌 Connector: Acts as the scheduling center, responsible for coordinating interactions between LLM and Vector Database, implemented based on Langchain technology.
- 📝 Prompt Control: Designs from development and operations perspectives, categorizes different problems, and adds backgrounds to prompts to ensure the controllability and completeness of answers.
- 💬 LLM: Uses GPT-3.5-turbo by default and provides proprietary model options for private deployments and other privacy-related scenarios.
- 🔤 Text Embedding: Uses OpenAI's Text Embedding model by default, supports private deployments and other privacy-related scenarios, and provides proprietary model options.
- 🚧 SandBox: For generated outputs, like code, to help users judge their authenticity, an interactive verification environment is provided (based on FaaS), allowing user adjustments.
For implementation details, see: Technical Route Details
模型接入
有需要接入的model,可以提issue
| model_name | model_size | gpu_memory | quantize | HFhub | ModelScope |
|---|---|---|---|---|---|
| chatgpt | - | - | - | - | - |
| codellama-34b-int4 | 34b | 20g | int4 | coming soon | link |
🚀 Quick Start
Please install the Nvidia driver yourself; this project has been tested on Python 3.9.18, CUDA 11.7, Windows, and X86 architecture macOS systems.
- Preparation of Python environment
- It is recommended to use conda to manage the python environment (optional)
# Prepare conda environment
conda create --name Codefusegpt python=3.9
conda activate Codefusegpt
- Install related dependencies
cd Codefuse-ChatBot
# python=3.9,use notebook-latest,python=3.8 use notebook==6.5.5
pip install -r requirements.txt
- Preparation of Sandbox Environment
-
Windows Docker installation: Docker Desktop for Windows supports 64-bit versions of Windows 10 Pro, with Hyper-V enabled (not required for versions v1903 and above), or 64-bit versions of Windows 10 Home v1903 and above.
-
Linux Docker Installation: Linux installation is relatively simple, please search Baidu/Google for installation instructions.
-
Mac Docker Installation
# Build images for the sandbox environment, see above for notebook version issues
bash docker_build.sh
- Model Download (Optional)
If you need to use open-source LLM and Embed
ding models, you can download them from HuggingFace. Here, we use THUDM/chatglm2-6b and text2vec-base-chinese as examples:
# install git-lfs
git lfs install
# install LLM-model
git lfs clone https://huggingface.co/THUDM/chatglm2-6b
# install Embedding-model
git lfs clone https://huggingface.co/shibing624/text2vec-base-chinese
- Basic Configuration
# Modify the basic configuration for service startup
cd configs
cp model_config.py.example model_config.py
cp server_config.py.example server_config.py
# model_config#11~12 If you need to use the openai interface, openai interface key
os.environ["OPENAI_API_KEY"] = "sk-xxx"
# You can replace the api_base_url yourself
os.environ["API_BASE_URL"] = "https://api.openai.com/v1"
# vi model_config#95 You need to choose the language model
LLM_MODEL = "gpt-3.5-turbo"
# vi model_config#33 You need to choose the vector model
EMBEDDING_MODEL = "text2vec-base"
# vi model_config#19 Modify to your local path, if you can directly connect to huggingface, no modification is needed
"text2vec-base": "/home/user/xx/text2vec-base-chinese",
# Whether to start the local notebook for code interpretation, start the docker notebook by default
# vi server_config#35, True to start the docker notebook, false to start the local notebook
"do_remote": False, / "do_remote": True,
- Start the Service
By default, only webui related services are started, and fastchat is not started (optional).
# if use codellama-34b-int4, you should replace fastchat's gptq.py
# cp examples/gptq.py ~/site-packages/fastchat/modules/gptq.py
# dev_opsgpt/service/llm_api.py#258 => kwargs={"gptq_wbits": 4},
# start llm-service(可选)
python dev_opsgpt/service/llm_api.py
cd examples
# python ../dev_opsgpt/service/llm_api.py If you need to use the local large language model, you can execute this command
bash start_webui.sh
🤗 Acknowledgements
This project is based on langchain-chatchat and codebox-api. We deeply appreciate their contributions to open source!