Codefuse-ChatBot: Development by Private Knowledge Augmentation
![]()
![]()


🔔 Updates
- [2023.12.01] Release of Multi-Agent and codebase retrieval functionalities.
- [2023.11.15] Addition of Q&A enhancement mode based on the local codebase.
- [2023.09.15] Launch of sandbox functionality for local/isolated environments, enabling knowledge retrieval from specified URLs using web crawlers.
📜 Contents
🤝 Introduction
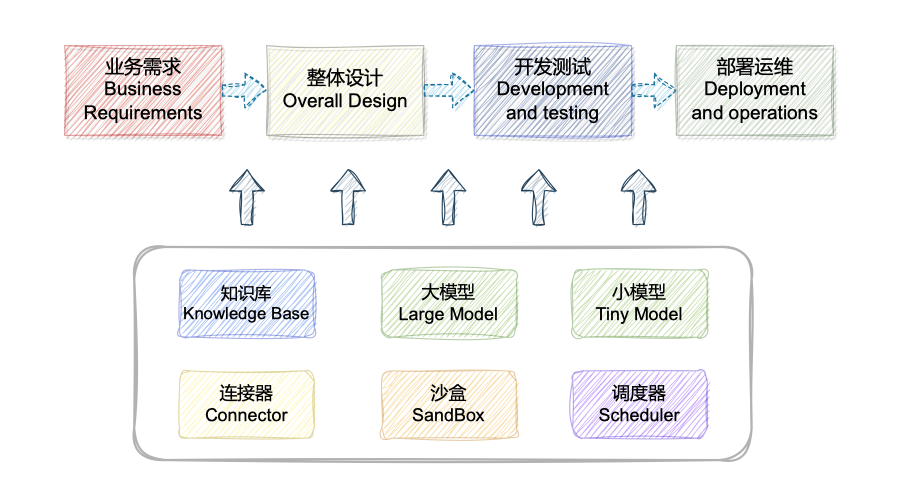
💡 The aim of this project is to construct an AI intelligent assistant for the entire lifecycle of software development, covering design, coding, testing, deployment, and operations, through Retrieval Augmented Generation (RAG), Tool Learning, and sandbox environments. It transitions gradually from the traditional development and operations mode of querying information from various sources and operating on standalone, disparate platforms to an intelligent development and operations mode based on large-model Q&A, changing people's development and operations habits.
- 🧠 Intelligent Scheduling Core: Constructed a well-integrated scheduling core system that supports multi-mode one-click configuration, simplifying the operational process.
- 💻 Comprehensive Code Repository Analysis: Achieved in-depth understanding at the repository level and coding and generation at the project file level, enhancing development efficiency.
- 📄 Enhanced Document Analysis: Integrated document knowledge bases with knowledge graphs, providing deeper support for document analysis through enhanced retrieval and reasoning.
- 🔧 Industry-Specific Knowledge: Tailored a specialized knowledge base for the DevOps domain, supporting the self-service one-click construction of industry-specific knowledge bases for convenience and practicality.
- 🤖 Compatible Models for Specific Verticals: Designed small models specifically for the DevOps field, ensuring compatibility with related DevOps platforms and promoting the integration of the technological ecosystem.
🌍 Relying on open-source LLM and Embedding models, this project can achieve offline private deployments based on open-source models. Additionally, this project also supports the use of the OpenAI API.
👥 The core development team has been long-term focused on research in the AIOps + NLP domain. We initiated the CodefuseGPT project, hoping that everyone could contribute high-quality development and operations documents widely, jointly perfecting this solution to achieve the goal of "Making Development Seamless for Everyone."
🌍 Relying on open-source LLM and Embedding models, this project can achieve offline private deployments based on open-source models. Additionally, this project also supports the use of the OpenAI API.
👥 The core development team has been long-term focused on research in the AIOps + NLP domain. We initiated the DevOpsGPT project, hoping that everyone could contribute high-quality development and operations documents widely, jointly perfecting this solution to achieve the goal of "Making Development Seamless for Everyone."
🧭 Technical Route
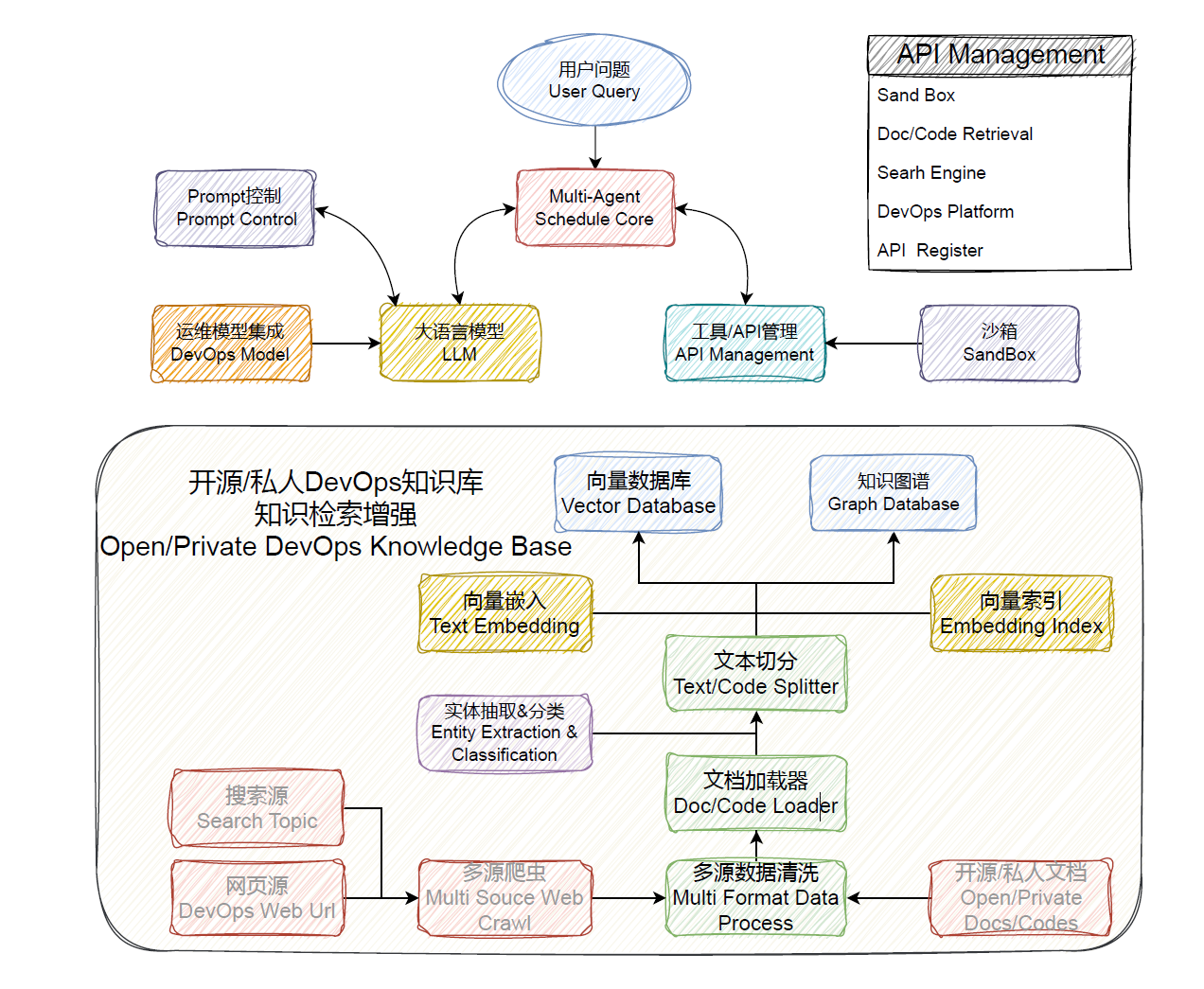
- 🧠 Multi-Agent Schedule Core: Easily configurable to create interactive intelligent agents.
- 🕷️ Multi Source Web Crawl: Offers the capability to crawl specified URLs for collecting the required information.
- 🗂️ Data Processor: Effortlessly handles document loading, data cleansing, and text segmentation, integrating data from different sources.
- 🔤 Text Embedding & Index::Users can easily upload files for document retrieval, optimizing the document analysis process.
- 🗄️ Vector Database & Graph Database: Provides flexible and powerful data management solutions.
- 📝 Prompt Control & Management::Precisely defines the contextual environment for intelligent agents.
- 🚧 SandBox::Safely executes code compilation and actions.
- 💬 LLM::Supports various open-source models and LLM interfaces.
- 🛠️ API Management:: Enables rapid integration of open-source components and operational platforms.
For implementation details, see: Technical Route Details
🌐 Model Integration
If you need to integrate a specific model, please inform us of your requirements by submitting an issue.
| model_name | model_size | gpu_memory | quantize | HFhub | ModelScope |
|---|---|---|---|---|---|
| chatgpt | - | - | - | - | - |
| codellama-34b-int4 | 34b | 20g | int4 | coming soon | link |
🚀 Quick Start
Please install the Nvidia driver yourself; this project has been tested on Python 3.9.18, CUDA 11.7, Windows, and X86 architecture macOS systems.
- Preparation of Python environment
- It is recommended to use conda to manage the python environment (optional)
# Prepare conda environment
conda create --name Codefusegpt python=3.9
conda activate Codefusegpt
- Install related dependencies
cd Codefuse-ChatBot
# python=3.9,use notebook-latest,python=3.8 use notebook==6.5.5
pip install -r requirements.txt
- Preparation of Sandbox Environment
-
Windows Docker installation: Docker Desktop for Windows supports 64-bit versions of Windows 10 Pro, with Hyper-V enabled (not required for versions v1903 and above), or 64-bit versions of Windows 10 Home v1903 and above.
-
Linux Docker Installation: Linux installation is relatively simple, please search Baidu/Google for installation instructions.
-
Mac Docker Installation
# Build images for the sandbox environment, see above for notebook version issues
bash docker_build.sh
- Model Download (Optional)
If you need to use open-source LLM and Embed
ding models, you can download them from HuggingFace. Here, we use THUDM/chatglm2-6b and text2vec-base-chinese as examples:
# install git-lfs
git lfs install
# install LLM-model
git lfs clone https://huggingface.co/THUDM/chatglm2-6b
# install Embedding-model
git lfs clone https://huggingface.co/shibing624/text2vec-base-chinese
- Basic Configuration
# Modify the basic configuration for service startup
cd configs
cp model_config.py.example model_config.py
cp server_config.py.example server_config.py
# model_config#11~12 If you need to use the openai interface, openai interface key
os.environ["OPENAI_API_KEY"] = "sk-xxx"
# You can replace the api_base_url yourself
os.environ["API_BASE_URL"] = "https://api.openai.com/v1"
# vi model_config#105 You need to choose the language model
LLM_MODEL = "gpt-3.5-turbo"
# vi model_config#43 You need to choose the vector model
EMBEDDING_MODEL = "text2vec-base"
# vi model_config#25 Modify to your local path, if you can directly connect to huggingface, no modification is needed
"text2vec-base": "shibing624/text2vec-base-chinese",
# vi server_config#8~14, it is recommended to start the service using containers.
DOCKER_SERVICE = True
# Whether to use container sandboxing is up to your specific requirements and preferences
SANDBOX_DO_REMOTE = True
# Whether to use api-service to use chatbot
NO_REMOTE_API = True
- Start the Service
By default, only webui related services are started, and fastchat is not started (optional).
# if use codellama-34b-int4, you should replace fastchat's gptq.py
# cp examples/gptq.py ~/site-packages/fastchat/modules/gptq.py
# dev_opsgpt/service/llm_api.py#258 => kwargs={"gptq_wbits": 4},
# start llm-service(可选)
python dev_opsgpt/service/llm_api.py
# After configuring server_config.py, you can start with just one click.
cd examples
bash start_webui.sh
🤗 Acknowledgements
This project is based on langchain-chatchat and codebox-api. We deeply appreciate their contributions to open source!