8.1 KiB
DevOps-ChatBot: Development by Private Knowledge Augmentation
![]()
![]()


本项目是一个开源的 AI 智能助手,专为软件开发的全生命周期而设计,涵盖设计、编码、测试、部署和运维等阶段。通过知识检索、工具使用和沙箱执行,DevOps-ChatBot 能解答您开发过程中的各种专业问题、问答操作周边独立分散平台。
🔔 更新
- [2023.09.15] 本地/隔离环境的沙盒功能开放,基于爬虫实现指定url知识检索
📜 目录
🤝 介绍
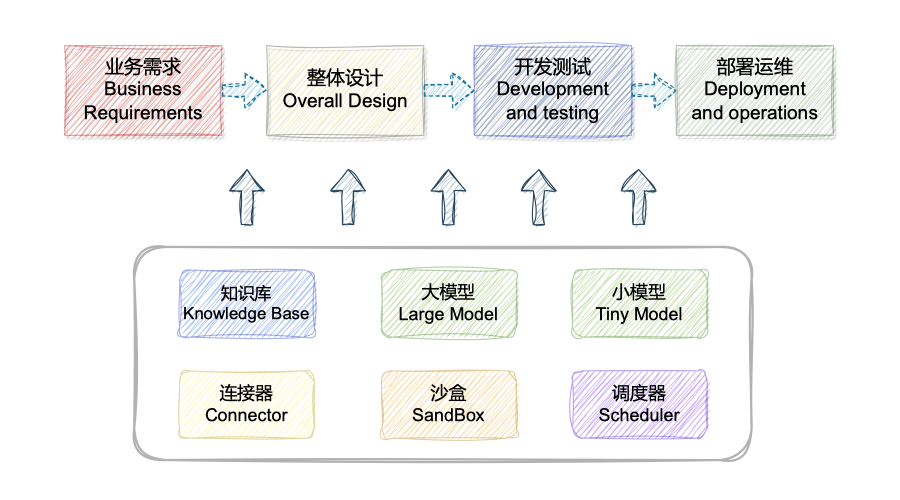
💡 本项目旨在通过检索增强生成(Retrieval Augmented Generation,RAG)、工具学习(Tool Learning)和沙盒环境来构建软件开发全生命周期的AI智能助手,涵盖设计、编码、测试、部署和运维等阶段。 逐渐从各处资料查询、独立分散平台操作的传统开发运维模式转变到大模型问答的智能化开发运维模式,改变人们的开发运维习惯。
- 📚 知识库管理:DevOps专业高质量知识库 + 企业级知识库自助构建 + 对话实现快速检索开源/私有技术文档
- 🐳 隔离沙盒环境:实现代码的快速编译执行测试
- 🔄 React范式:支撑代码的自我迭代、自动执行
- 🛠️ Prompt管理:实现各种开发、运维任务的prompt管理
- 🚀 对话驱动:需求设计、系分设计、代码生成、开发测试、部署运维自动化
🌍 依托于开源的 LLM 与 Embedding 模型,本项目可实现基于开源模型的离线私有部署。此外,本项目也支持 OpenAI API 的调用。
👥 核心研发团队长期专注于 AIOps + NLP 领域的研究。我们发起了 DevOpsGPT 项目,希望大家广泛贡献高质量的开发和运维文档,共同完善这套解决方案,以实现“让天下没有难做的开发”的目标。
🎥 演示视频
为了帮助您更直观地了解 DevOps-ChatBot 的功能和使用方法,我们录制了一个演示视频。您可以通过观看此视频,快速了解本项目的主要特性和操作流程。
🧭 技术路线
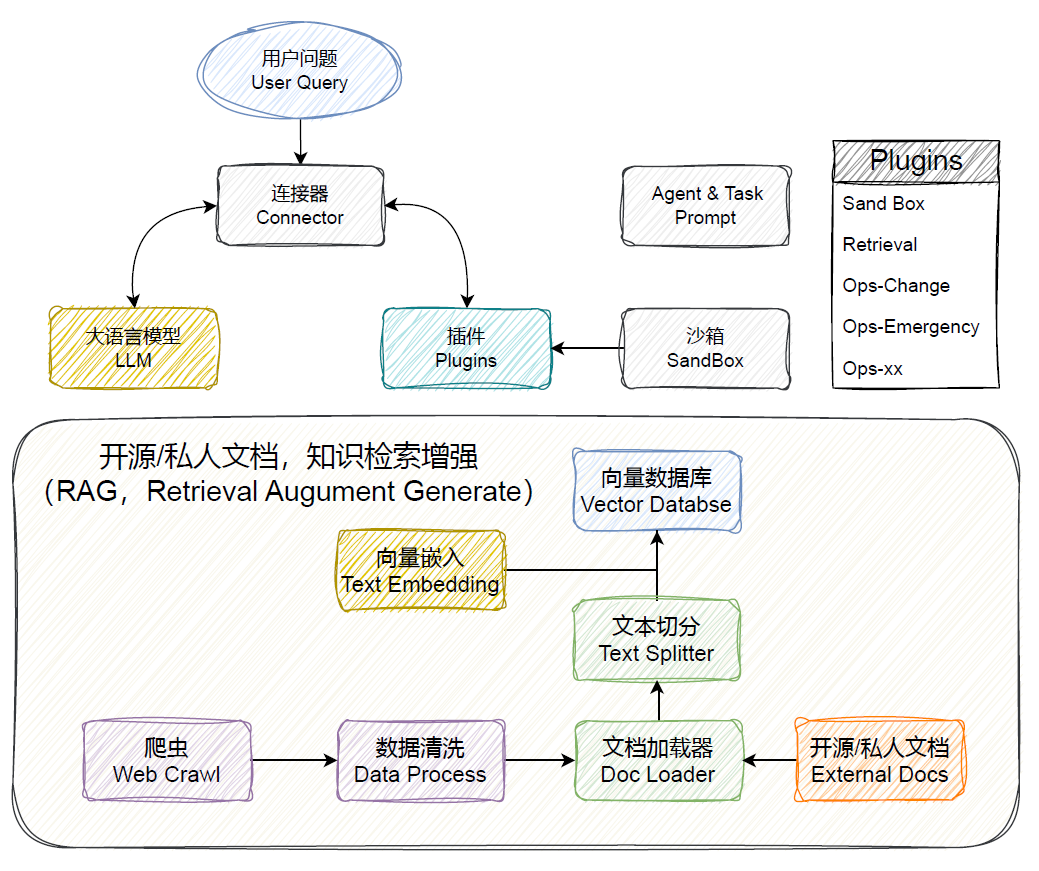
- 🕷️ Web Crawl:实现定期网络文档爬取,确保数据的及时性,并依赖于开源社区的持续补充。
- 🗂️ DocLoader & TextSplitter:对从多种来源爬取的数据进行数据清洗、去重和分类,并支持私有文档的导入。
- 🗄️ Vector Database:结合Text Embedding模型对文档进行Embedding并在Milvus中存储。
- 🔌 Connector:作为调度中心,负责LLM与Vector Database之间的交互调度,基于Langchain技术实现。
- 📝 Prompt Control:从开发和运维角度设计,为不同问题分类并为Prompt添加背景,确保答案的可控性和完整性。
- 💬 LLM:默认使用GPT-3.5-turbo,并为私有部署和其他涉及隐私的场景提供专有模型选择。
- 🔤 Text Embedding:默认采用OpenAI的Text Embedding模型,支持私有部署和其他隐私相关场景,并提供专有模型选择。
- 🚧 SandBox:对于生成的输出,如代码,为帮助用户判断其真实性,提供了一个交互验证环境(基于FaaS),并支持用户进行调整。
具体实现明细见:技术路线明细
🚀 快速使用
请自行安装 nvidia 驱动程序,本项目已在 Python 3.9.18,CUDA 11.7 环境下,Windows、X86 架构的 macOS 系统中完成测试。
1、python 环境准备
- 推荐采用 conda 对 python 环境进行管理(可选)
# 准备 conda 环境
conda create --name devopsgpt python=3.9
conda activate devopsgpt
- 安装相关依赖
cd DevOps-ChatBot
pip install -r requirements.txt
# 安装完成后,确认电脑是否兼容 notebook=6.5.5 版本,若不兼容执行更新命令
pip install --upgrade notebook
# 修改 docker_requirement.txt 的 notebook 版本设定, 用于后续构建新的孤立镜像
notebook=6.5.5 => notebook
2、沙盒环境准备
-
windows Docker 安装: Docker Desktop for Windows 支持 64 位版本的 Windows 10 Pro,且必须开启 Hyper-V(若版本为 v1903 及以上则无需开启 Hyper-V),或者 64 位版本的 Windows 10 Home v1903 及以上版本。
-
Linux Docker 安装: Linux 安装相对比较简单,请自行 baidu/google 相关安装
-
Mac Docker 安装
# 构建沙盒环境的镜像,notebook版本问题见上述
bash docker_build.sh
3、模型下载(可选)
如需使用开源 LLM 与 Embedding 模型可以从 HuggingFace 下载。 此处以 THUDM/chatglm2-6bm 和 text2vec-base-chinese 为例:
# install git-lfs
git lfs install
# install LLM-model
git lfs clone https://huggingface.co/THUDM/chatglm2-6b
# install Embedding-model
git lfs clone https://huggingface.co/shibing624/text2vec-base-chinese
4、基础配置
# 修改服务启动的基础配置
cd configs
cp model_config.py.example model_config.py
cp server_config.py.example server_config.py
# model_config#11~12 若需要使用openai接口,openai接口key
os.environ["OPENAI_API_KEY"] = "sk-xxx"
# 可自行替换自己需要的api_base_url
os.environ["API_BASE_URL"] = "https://api.openai.com/v1"
# vi model_config#95 你需要选择的语言模型
LLM_MODEL = "gpt-3.5-turbo"
# vi model_config#33 你需要选择的向量模型
EMBEDDING_MODEL = "text2vec-base"
# vi model_config#19 修改成你的本地路径,如果能直接连接huggingface则无需修改
"text2vec-base": "/home/user/xx/text2vec-base-chinese",
# 是否启动本地的notebook用于代码解释,默认启动docker的notebook
# vi server_config#35,True启动docker的notebook,false启动local的notebook
"do_remote": False, / "do_remote": True,
5、启动服务
默认只启动webui相关服务,未启动fastchat(可选)。
# 若需要支撑codellama-34b-int4模型,需要给fastchat打一个补丁
# cp examples/gptq.py ~/site-packages/fastchat/modules/gptq.py
# start llm-service(可选)
python dev_opsgpt/service/llm_api.py
cd examples
# python ../dev_opsgpt/service/llm_api.py 若需使用本地大语言模型,可执行该命令
bash start_webui.sh
🤗 致谢
本项目基于langchain-chatchat和codebox-api,在此深深感谢他们的开源贡献!